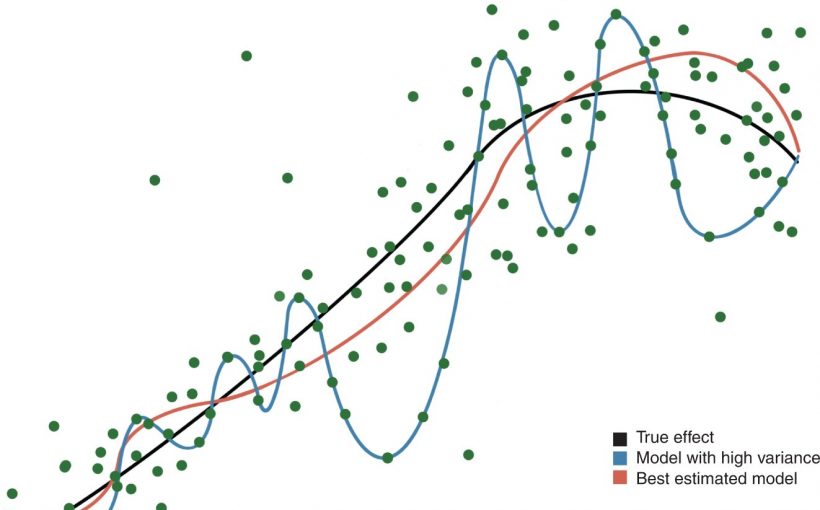
 and a true effect (black line), a statistical model aims to estimate the true effect. The red line exemplifies a close estimation, whereas the blue line exemplifies an overfit ML model with over-reliance on outliers. Such a model might seem to provide excellent results for this particular dataset, but fails to perform well in a different (external) dataset. Credit: <i>Nature Medicine</i> (2022). DOI: 10.1038/s41591-022-01961-6")
An international team of researchers, writing in the journal Nature Medicine, advises that strong care needs to be taken not to misuse or overuse machine learning (ML) in health care research.
“I absolutely believe in the power of ML but it has to be a relevant addition,” said neurosurgeon-in-training and statistics editor Dr. Victor Volovici, first author of the comment, from Erasmus MC University Medical Center, The Netherlands. “Sometimes ML algorithms do not perform better than traditional statistical methods, leading to the publication of papers that lack clinical or scientific value.”
Real world examples have shown that the misuse of algorithms in health care could perpetuate human prejudices or inadvertently cause harm when the machines are trained on biased datasets.
“Many believe ML will revolutionize health care because machines make choices more objectively than humans. But without proper oversight, ML models may do more harm than good,” said Associate Professor Nan Liu, senior author of the comment, from the Center for Quantitative Medicine and Health Services & Systems Research Program at Duke-NUS Medical School, Singapore.
“If, through ML, we uncover patterns that we otherwise would not see—like in radiology and pathology images—we should be able to explain how the algorithms got there, to allow for checks and balances.”
Together with a group of scientists from the U.K. and Singapore, the researchers highlight that although guidelines have been formulated to regulate the use of ML in clinical research, these guidelines are only applicable once a decision to use ML has been made and do not ask whether or when its use is appropriate in the first place.
For example, companies have successfully trained ML algorithms to recognize faces and road objects using billions of images and videos. But when it comes to their use in health care settings, they are often trained on data in the tens, hundreds or thousands. “This underscores the relative poverty of big data in health care and the importance of working toward achieving sample sizes that have been attained in other industries, as well as the importance of a concerted, international big data sharing effort for health data,” the researchers write.
Another issue is that most ML and deep learning algorithms (that do not receive explicit instructions regarding the outcome) are often still regarded as a “black box.” For example, at the start of the COVID-19 pandemic, scientists published an algorithm that could predict coronavirus infections from lung photos. Afterwards, it turned out that the algorithm had drawn conclusions based on the imprint of the letter “R” (for “Right Lung”) in the photos, which was always found in a slightly different spot on the scans.
“We have to get rid of the idea that ML can discover patterns in data that we cannot understand,” said Dr. Volovici about the incident. “ML can very well discover patterns that we cannot see directly, but then you have to be able to explain how you came to that conclusion. In order to do that, the algorithm has to be able to show what steps it took, and that requires innovation.”
The researchers advise that ML algorithms should be evaluated against traditional statistical approaches (when applicable) before they are used in clinical research. And when deemed appropriate, they should complement clinician decision-making, rather than replace it. “ML researchers should recognize the limits of their algorithms and models in order to prevent their overuse and misuse, which could otherwise sow distrust and cause patient harm,” the researchers write.
Source: Read Full Article